高维数据的有效维度
协方差矩阵
设随机向量 $\mathbf{x} \in \mathbb{R}^d$ 表示空间中的数据点,其均值为 $\boldsymbol{\mu} = \mathbb{E}[\mathbf{x}]$。协方差矩阵 $\Sigma \in \mathbb{R}^{d \times d}$ 定义为:
\[\Sigma = \mathbb{E}\left[ (\mathbf{x} - \boldsymbol{\mu})(\mathbf{x} - \boldsymbol{\mu})^\top \right]\]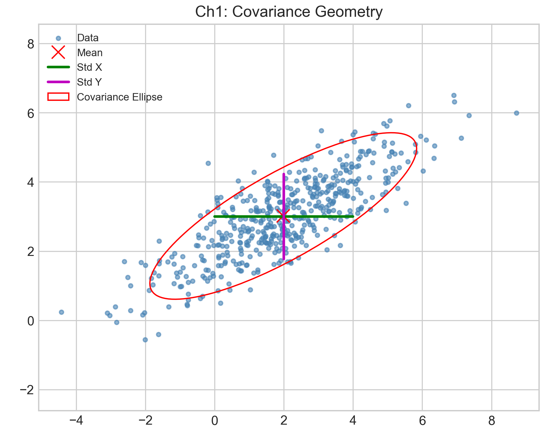
$\Sigma$ 是一个实对称半正定矩阵,其元素 $\Sigma_{ij}$ 具有明确的统计与几何含义:
方差(对角线元素 $\Sigma_{ii}$): \(\Sigma_{ii} = \text{Var}(x_i) = \mathbb{E}[(x_i - \mu_i)^2]\) 它衡量了数据在第 $i$ 个标准基向量方向上的离散程度。在信号处理视角下 variance 对应于该维度携带的信号能量。若 $\Sigma_{ii} \approx 0$,则该维度近似为常数,不具备区分不同样本的信息能力。
协方差(非对角线元素 $\Sigma_{ij}, i \neq j$): \(\Sigma_{ij} = \text{Cov}(x_i, x_j) = \mathbb{E}[(x_i - \mu_i)(x_j - \mu_j)]\) 它量化了维度 $i$ 与维度 $j$ 之间的线性相关性。若 $\Sigma_{ij \neq 0}$,表明两个维度存在冗余信息。
谱分解
由于 $\Sigma$ 是实对称半正定矩阵,根据谱定理(Spectral Theorem),存在正交矩阵 $U = [\mathbf{u}_1, \dots, \mathbf{u}_d]$ 和对角矩阵 $\Lambda = \text{diag}(\lambda_1, \dots, \lambda_d)$,使得:
\[\Sigma = U \Lambda U^\top = \sum_{i=1}^d \lambda_i \mathbf{u}_i \mathbf{u}_i^\top\]其中:
- $\lambda_1 \ge \lambda_2 \ge \dots \ge \lambda_d \ge 0$ 为特征值,代表数据在对应特征向量方向上的方差。
- $\mathbf{u}_i$ 为对应的单位特征向量,构成一组新的正交基。
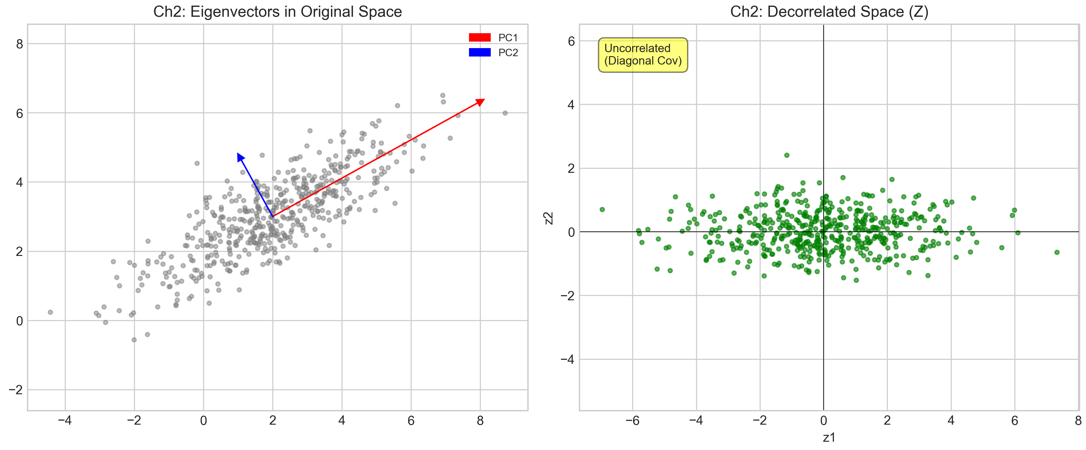
去相关: 原始坐标系下的维度间存在耦合(非对角项非零)。通过线性变换 $\mathbf{z} = U^\top (\mathbf{x} - \boldsymbol{\mu})$ 投影到特征基上后,新变量 $\mathbf{z}$ 的协方差矩阵变为对角阵 $\Lambda$。这意味着在新坐标系下各维度统计独立(在线性意义下实现了解耦)。
主成分与能量排序: 特征值 $\lambda_i$ 单调递减排列,反映了数据沿各主成分方向的能量分布。前 $k$ 个大特征值对应的子空间通常包含了数据的主要变异信息。若数据本质上位于低维流形上则大部分 $\lambda_i$ 将趋近于零。
累积方差贡献率
传统的主成分分析(PCA)常采用“累积方差贡献率确定有效维度 $k$,即寻找最小的 $k$使得:
\[\frac{\sum_{i=1}^k \lambda_i}{\sum_{j=1}^d \lambda_j} > \theta\]其中 $\theta$ 为预设阈值(如 0.95)。
参与率(Participation Ratio):有效维度的度量
参与率(Participation Ratio, PR)是有效维度 $d_{eff}$ 的连续度量指标:
\[d_{eff} = \frac{\left( \sum_{i=1}^d \lambda_i \right)^2}{\sum_{i=1}^d \lambda_i^2} = \frac{\|\boldsymbol{\lambda}\|_1^2}{\|\boldsymbol{\lambda}\|_2^2}\]该公式源自凝聚态物理中用于衡量波函数局域化程度的逆参与率(Inverse Participation Ratio, IPR)的倒数。
情形 I:各向同性分布 假设所有维度同等重要,即 $\lambda_1 = \lambda_2 = \dots = \lambda_d = c > 0$。
\[d_{eff} = \frac{(dc)^2}{d c^2} = \frac{d^2 c^2}{d c^2} = d\]结论:当频谱平坦时,有效维度等于原始空间维度,表明所有自由度均被充分利用。
情形 II:极端稀疏分布 假设仅有一个主导模式,即 $\lambda_1 = c, \lambda_{i>1} = 0$。
\[d_{eff} = \frac{c^2}{c^2} = 1\]结论:当能量集中在单一维度时,有效维度为 1,准确反映了数据的秩-1特性。
