碎片收集者Bernkastel
碎片收集者Bernkastel
基本原理
全文:间隔重复
 不带回忆的遗忘曲线,指数级衰减
不带回忆的遗忘曲线,指数级衰减
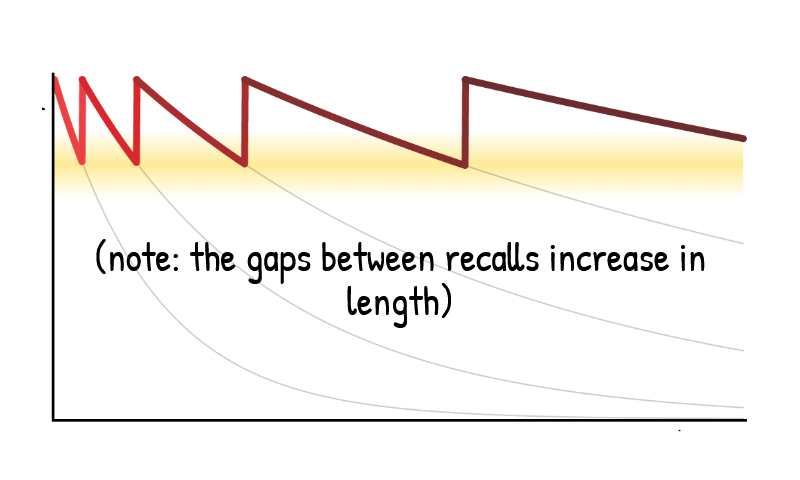 在黄色区域(不是太难,也不是太简单,难度刚刚好)主动回忆的遗忘曲线,半衰期变长。
在黄色区域(不是太难,也不是太简单,难度刚刚好)主动回忆的遗忘曲线,半衰期变长。
同样回忆次数的情况下,效率最大化的方式是逐渐拉长复习时间,并根据每次的难度反馈调整。
卡片特性
理想的Anki卡片如同拼图的碎片,
- 小: 每一张都包含一个独立的知识点,
- 可相互连接: 但又能与其他卡片相互关联,共同构成一个完整的知识体系,
- 有意义: 并且每个碎片本身都承载着明确的学习价值。 这种方法有助于学习者构建知识网络,而非孤立地记忆零散信息。


流程
提取内容
Python库:
PyPDF2pdfplumberPyMuPDF4LLM
Prompt_1
- 阶段一:提取核心事实。
1 2 3 4 5
请从以上文本中提取所有独立的核心事实和关键概念,以要点的形式列出。 确保每个要点都是一个原子化的信息单元。 确保信息单元之间具有逻辑上的递进关系,并能覆盖所有关键知识点。 [此处粘贴教材中的一节内容]
- 阶段二:基于事实生成卡片。
1 2 3 4 5 6
根据以上核心事实列表,为每一个事实生成一张Anki卡片。请遵循以下规则: 卡片类型:“基本卡片”或“填空题(Cloze Deletion)” 原子化: 每张卡片只测试一个知识点。 上下文独立:每张卡片都应包含足够的信息,使其在没有上下文的情况下也能被理解。 促进关联:在答案或额外字段中,可以适当地引导思考与其他概念的联系。 输出格式:使用分号或制表符分隔问题和答案,以便于导入Anki。例如:问题1;答案1
Prompt_2
1
2
3
4
5
6
7
8
9
10
请从上传的文件中提取所有独立的核心事实和关键概念。
确保信息单元之间具有逻辑上的递进关系,并能覆盖所有关键知识点。
为每一个信息单元生成一张Anki卡片。请遵循以下规则:
卡片类型:基本卡片
原子化: 每张卡片只测试一个知识点。
上下文独立:每张卡片都应包含足够的信息,使其在没有上下文的情况下也能被理解。
促进关联:在答案中,可以适当地引导思考与其他概念的联系。
遵循 Small Connected Meaningful 原则
输出语言:简体中文
输出格式:使用分号分隔问题和答案,以便于导入Anki。例如:问题1;答案1
图片和公式
- 图片: 对于图表、示意图等,可以使用工具(如PyMuPDF4LLM)将图片从PDF中提取出来。一些自动化工具如Anki Decks已经支持自动创建图片遮挡题。
- 公式: 使用支持LaTeX的Anki插件
生成并导入Anki
生成一个可以被Anki识别的文本文件(如CSV或TXT)。 确保文件中的分隔符(如分号、逗号或制表符)与在Anki导入时选择的一致。
例子
二分类器指标
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
#separator:tab
#html:true
混淆矩阵比较什么? 比较模型的<b>预测结果</b>与<b>真实情况</b>。
混淆矩阵中的 TP (True Positive) 代表什么? 真实为+,预测也为+<br> (真的有病,模型也说有病)。
混淆矩阵中的 TN (True Negative) 代表什么? 真实为-,预测也为- <br>(真的没病,模型也说没病)。
混淆矩阵中的 FP (False Positive) 代表什么? 真实为-,预测为+ <br>(真的没病,模型说有病)。
混淆矩阵中的 FN (False Negative) 代表什么? 真实为+,预测为- <br>(真的有病,模型说没病)。
混淆矩阵中 T/F 和 P/N 的命名规则是什么? 第一个字母(T/F)代表预测是否正确;<br>第二个字母(P/N)代表模型做出的预测是什么。
FP (False Positive) 通常被称为什么? 误报 (或 假阳性)。
FN (False Negative) 通常被称为什么? 漏报 (或 假阴性)。
准确率 (Accuracy) 的一句话定义是什么? 所有样本中,模型预测正确的比例是多少?<br>混淆矩阵对角线的占比。
在什么情况下,准确率 (Accuracy) 是一个有误导性的指标? 在数据类别不均衡时。<br>例:1000个人里只有1个病人,预测全健康的准确率有99.9%。
精度 (Precision) 的一句话定义是什么? 所有被模型【预测为+】的样本中,真正是+例的比例。<br><br>关心【不误报】,可以理解为“宁可放过,不可杀错”。
在【垃圾邮件过滤】或【股票推荐】场景中,更关注精度还是召回率?为什么? 精度 (Precision)。<br>因为【误报】(FP) 的代价极其高昂<br>(将重要邮件判为垃圾或推荐了错误的股票)。
召回率 (Recall) 的一句话定义是什么? 所有【真实为+】的样本中,被模型成功找出来的比例。<br>关心【不漏报】,可以理解为“宁可杀错,不可放过”。
在【疾病诊断】或【金融反欺诈】场景中,更关注精度还是召回率?为什么? 召回率 (Recall)。<br>因为【漏报】(FN) 的代价极其高昂<br>(漏掉病人或欺诈交易)。
要提高精度,模型需要如何? 模型需要变得更“苛刻”,只有非常有把握时才预测为Positive。<br>这会导致一些模棱两可的样本被放弃,从而降低召回率。
要提高召回率,模型需要如何? 模型需要变得更“宽松”,尽可能多地将样本预测为Positive。<br>这会导致一些本不该是Positive的样本被误判,从而降低精度。
为什么说精度 (Precision) 和召回率 (Recall) 是一对矛盾的指标? 提高精度(要求更严格)通常会牺牲召回率(漏掉更多);<br>提高召回率(放宽标准)通常会牺牲精度(误报更多)。
F1-Score 的一句话定义是什么? 精度 (Precision) 和召回率 (Recall) 的调和平均数,<br>一个兼顾两者的综合指标。
准确率 (Accuracy) 的公式是什么? (TP + TN) / (TP + TN + FP + FN)
精度 (Precision) 的公式是什么? TP / (TP + FP)
召回率 (Recall) 的公式是什么? TP / (TP + FN)
F1-Score 的公式是什么? 2 * (Precision * Recall) / (Precision + Recall)
如果你希望同时关注精度和召回率,应该使用哪个综合指标? F1-Score。
ROC曲线的全称是什么? ROC曲线 (Receiver Operating Characteristic Curve)
ROC 曲线的横轴和纵轴分别是什么? 横轴:假阳性率 (FPR = FP / (FP+TN));纵轴:真阳性率 (TPR = TP / (TP+FN)),也就是召回率。
AUC 的全称是什么? Area Under the Curve (ROC曲线下面积)。
AUC 指标的核心优点是什么? 它不受<b>类别不均衡</b>和<b>分类阈值</b>的影响,能全面评估模型的整体排序能力。
AUC=0.5 代表什么? 模型性能相当于<b>随机猜测</b>。
AUC=1 代表什么? 模型是<b>完美</b>的分类器。
当需要评估模型整体的【排序能力】而非特定阈值下的表现时,哪个指标最合适? AUC。

本文由作者按照 CC BY 4.0 进行授权